
Los retos de aplicar Inteligencia Artificial
El avance imparable de la inteligencia artificial (IA) está creando una brecha cada vez mayor entre las empresas que la han adoptado y las que todavía están empezando. También en aquellos que han empezado por una prueba de concepto que no ha tenido el gran resultado inmediato esperado, pueden experimentarlo como una pequeña frustración y tomar una estrategia de “esperar y ver”.
El concepto de J Curve del profesor Erik Brynjolfsson (Stanford) define a la perfección esta fase inicial:
“Estas inversiones y cambios a menudo toman varios años y, durante este período, no producen resultados tangibles. Durante esta fase, las empresas están creando “activos intangibles”. Por ejemplo, podrían estar capacitando a su fuerza laboral para emplear estas nuevas tecnologías. Podrían estar rediseñando sus fábricas o equipándolas con nuevas tecnologías de sensores para aprovechar los modelos de aprendizaje automático. Es posible que necesiten renovar su infraestructura de datos y crear lagos de datos en los que puedan entrenar y ejecutar modelos de machine learning (ML). Estos esfuerzos pueden costar millones de dólares (o miles de millones en el caso de grandes corporaciones) y no generar cambios en la producción de la empresa a corto plazo.”
Todo esto hace que el gap sea cada vez más grande entre los convencidos y los que esperan. Como indica una investigación reciente del McKinsey Global Institute, existe una brecha real y creciente entre los líderes y los rezagados en la aplicación de la IA tanto en los sectores como dentro de ellos.
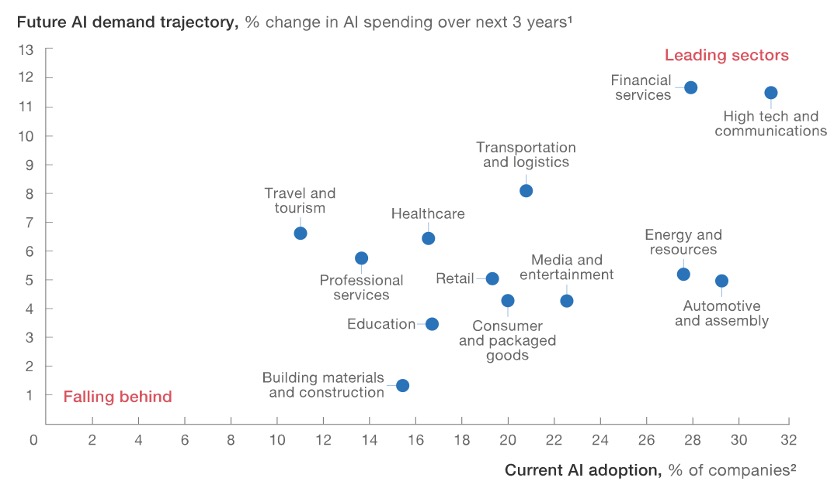
Precisamente, entre los retos más comunes que se encuentran las empresas al iniciar proyectos de IA está la falta de datos o la falta de personal especializado, y en algunos casos, ambas cosas, requiriendo de grandes inversiones iniciales.

La mayoría de los modelos de IA actuales se entrenan a través del "aprendizaje supervisado". Esto significa que los humanos deben etiquetar y categorizar los datos, lo que puede ser una tarea considerable. Los enfoques no supervisados reducen la necesidad de grandes conjuntos de datos etiquetados pero la realidad es que en muchos casos de uso no los podemos aplicar. El uso de modelos supervisados o no supervisados está intrínsecamente ligado al caso de uso (ver Machine learning explained para ampliar información).
Además, las técnicas más avanzadas de aprendizaje automático como el aprendizaje profundo (o Deep Learning, en inglés) requieren conjuntos de datos de entrenamiento que no solo estén etiquetados, sino que también sean lo suficientemente grandes y completos. Los conjuntos de datos masivos pueden ser difíciles de obtener o crear. Tanto la obtención masiva de datos como su preparación y etiquetado pueden suponer una importante inversión.
Sin olvidarnos del reto del talento. En este caso podemos suplir las carencias a corto plazo mediante externalización. Pero delegar externamente la totalidad de la IA puede ser un error colosal para las empresas.
Los líderes empresariales que esperan reducir la brecha deben poder abordar la IA de manera informada. Es decir, deben ser capaces de comprender por sí mismos dónde la IA puede conducir al crecimiento de los ingresos o capturar eficiencias. También saber distinguir dónde la IA no proporciona valor.
Además, ya hemos comentado que ellos (y no los perfiles técnicos) son responsables de comprender y resolver el desafío de la “última milla” de incorporar IA en productos y procesos.
Son retos que señalan un roadmap de varios años para las empresas. Ese camino difícilmente nos lo podremos ahorrar. Pero sí que podemos empezar a utilizar y experimentar rápidamente con herramientas de aprendizaje automático, conjuntos de datos y modelos entrenados para aplicaciones estándar, los cuales están ampliamente disponibles.
Se trata de la inteligencia artificial lista para usar o AI off-the-shelf (“lista para usar”), la cual incluye, por ejemplo, modelos de detección y creación de lenguaje natural y de visión artificial. A veces vienen en código abierto y en otros casos a través de interfaces de programación de aplicaciones (API) creadas por empresas pioneras como OpenAI o grandes proveedores de cloud público como AWS, Microsoft o Google.
A continuación, mostramos los principales casos de uso que nos ofrece la tecnología AI off-the-shelf de AWS.

Ya hay empresas que están implementado soluciones AI off-the-shelf, ya sea utilizando modelos de lenguaje natural, como el chatbots de atención a estudiantes que desarrollamos para la Generalitat de Cataluña llamado PauBot; o la soluciones de visión artificial, como el sistema de validación de identidades para evaluaciones online que hemos desarrollado para una importante universidad online y que ha ayudado a reducir el fraude en exámenes no presenciales.
En la práctica, tenemos que ser capaces de combinar ambos enfoques y contar con las capacidades necesarias para diseñar la solución ideal en cada caso. Para casos de uso estandarizados, disponemos de los modelos AI off-the-shelf que podemos implementar con capacidades de arquitectura cloud y arquitectura de datos, trabajando conjuntamente con los expertos de dominio.
Para casos no estandarizados, deberemos disponer además de capacidades de data science que nos acompañen en la decisión y creación del modelo de inteligencia artificial.

La promesa de la IA es inmensa y las tecnologías que la deben hacer realidad todavía están en desarrollo.
Si sabes que ahora es el momento de pensar en la supervivencia del negocio a largo plazo y posicionarse en la nueva era de las empresas data-driven, contáctanos y trataremos de ayudarte. Sin olvidar los retos de la aplicación de inteligencia artificial más customizada y ambiciosa con data science, podemos basarnos en la IA off-the-shelf para resolver diversos casos de uso de una forma realmente rápida y eficaz.
Si quieres leer los artículos anteriores de esta serie, recuerda que hemos explicado el desafío de los datos, hemos enumerado los 4 tipos de datos para aplicar IA y explicado la importancia de los 3 roles de conocimiento entre los miembros del equipo.








